¿Que hay de los métodos de analísis, control de versiones, normas de programación, UML, etc..? Nadie nos cuenta nada en ESPAÑOL que no sea pura teoria, algun ejemplo práctico no nos vendría mal. Creo que un blog sobre esto no sería mala idea.Mi opinión sobre estos temas, en general, es bastante singular. Estoy convencido de que "el emperador está desnudo", en la mayoría de los temas mencionados. Ocurre, sin embargo, que durante todos estos años, he gritado eso mismo unas cuantas veces, refiriéndome a distintos "emperadores", y ha resultado que, con las inevitables excepciones, tenía razón. Esto puede inducir a pensar que me he aficionado al deporte de detectar emperadores en bolas. Estas actitudes son adictivas, hay que reconocerlo. Por estos motivos, tanto por vosotros como por mí, quiero explicar mis razones de mi escepticismo. Prometo enlazar el tema con cualquier refutación que tengáis a bien escribir. Porque en definitiva, si estoy equivocado, soy el primer interesado en saberlo.
Voy a centrarme en UML. ¿Qué es UML? Se supone que es un convenio gráfico para representar determinados aspectos de sistemas. Hasta ahí, todos de acuerdo. Ahora viene la parte que la gente deduce por su cuenta. En realidad, según la persona, se pueden dar por asumidas ciertas "verdades", no necesariamente equivalentes o compatibles entre sí. Por ejemplo:
- UML debería ser utilizado sistemáticamente en la fase de análisis.
¡Falso! En realidad, el formalismo usado para las distintas fases del proceso de desarrollo debería ser lo más uniforme posible. Esto no es idea mía, por cierto: es Bertrand Meyer 100%. En sus libros, Meyer muestra cómo su Eiffel puede ser usado en todas las fases del desarrollo. Claro, Eiffel es un lenguaje que se presta especialmente para este uso.Los gráficos, en todo caso, tienen sentido, pero como método de apoyo, para cristalizar (por decirlo de algún modo) ideas e intuiciones... y sobre todo, como medio de comunicación con posibles expertos en el sistema modelado que no necesariamente conozcan lo suficiente de Informática. Cuando hay que sufrir un jefe de proyecto que no tiene ni zorra idea de programación, es preferible "obligar" al individuo para que use UML con nosotros, para intentar que lo que diga tenga un mínimo de estructuración y formalismo.- Los gráficos, en general, y UML en particular, tienen un "nosequé" que lo hacen más potente que cualquier formalismo basado en texto.
Eso puede ser verdad en el kindergarten, e incluso tengo serias dudas sobre si los críos entienden mejor un dibujo que una explicación verbal. ¡Por favor!, hay que recordar que la Civilización llegó cuando la gente dejó de dibujar bisontes en las paredes de la cueva y aprendió a escribir cosas como: "Churri, no te olvides de pasar por la carnicería".Ocurre, además, que UML, como formalismo, cojea. Preguntas retóricas para una calurosa tarde de mayo:
- ¿Cuántos tipos de gráficos ofrece UML?
- ¿Cuántos de estos tipos suele usted ver en libros de Informática (excepto en los que se dedican a explicar el propio UML)?
- ¿Cuántos de ellos son verdaderamente útiles?
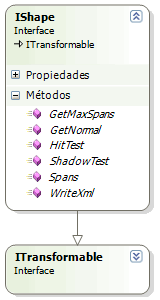
¿Verdaderamente útiles? Los diagramas de clases. Sin embargo, la gente suele confundirse con las cardinalidades de las relaciones, o se centra exclusivamente en la herencia. De todos modos, un diagrama de clases es útil, aunque al final... cuando se trate de bases de datos, la gente termine prefiriendo los clásicos diagramas de "patas de gallo".
¿Qué otro tipo de diagrama ofrece UML que realmente merezca la pena usar? Un servidor suele incluir algunos diagramas de secuencia en libros y cursos. ¿Sabe por qué lo hago? ¡Porque son tan raros y complicados que estoy seguro de que, cuando el lector se rompe la cabeza para descifrarlos, está repensando el contenido que ya he contado en el texto! Decían los antiguos romanos que, quien escribe, lee dos veces. Digo yo que, quien escudriña un diagrama de secuencias, piensa en el problema subyacente unas cuarenta veces más.
Seamos sinceros: ¿qué entiende usted mejor? ¿Cuatro líneas de pseudo código, o un intrincado diagrama de secuencias?
Otros tipos de gráficos, de tan triviales, terminan por parecer infantiles. Estoy pensando en los "use cases": un muñeco hecho con palotes y óvalos con textos encerrados. Los diagramas de estados tienen un poco más de sentido, pero esta vez, las reglas y convenios de UML son tan enrevesadas, y los propios gráficos tan parecidos a otros gráficos de UML, que al final la gente termina por dibujarlos como le da la gana, y guiándose por la dirección desde donde sopla el viento.
Hay otro problema importantísimo: UML fue diseñado por gente que usaba C++ como lenguaje de programación. C++ es muy potente, muy eficiente... pero su expresividad y claridad, sinceramente, dejan mucho que desear. Luego esa misma gente se aficionó a Java. Cuando alguien que trabaja en C# (¡o incluso en Delphi!) se enzarza con un diagrama UML en la fase de diseño, descubre importantes carencias. ¿Cómo se representa un evento en un diagrama de secuencias, por ejemplo? Claro, se puede alegar que UML no debería trabajar en ese nivel de detalles. Bravo. Estupendo. Pero entonces, ¿qué utilidad me puede proporcionar en la fase de diseño, una vez que el jefe lego en programación se ha encerrado en su despacho a jugar al Solitario?
Seguramente a esta explicación le faltan argumentos. Lo bueno de una bitácora es que no te obliga a vaciarte los bolsillos en un único mensaje. Me he centrado en UML para simplificar... pero algo parecido, y en ocasiones incluso peor, ocurre en otras áreas del mundillo de la "ingeniería de software".
Por ejemplo, la mayoría del contenido de la nueva moda, eso que llaman extreme programming, método Agile, etc, etc, es, o reglas triviales que nada aportan como novedad... o simplemente disparates. A mí se me cayó el alma al suelo hace un par de años cuando vi que Borland comenzaba a publicar en la página de su community sesudos artículos sobre la conveniencia... ¡de usar colores en los diagramas de software! Otra moda: la idea de la test-driven programming. Esta vez, hay un núcleo importante de verdad detrás del método. Pero para que la gente compre libros y software, y para que sus propagadores ganen dinero, el núcleo verdadero de la metodología test driven (que tiene mucha relación con la programación por contrato, la verificabilidad, etc, etc) se ha recubierto con capas y capas de fundamentalismo y tontería. Hay aplicaciones que admiten la metodología test driven, es cierto. También es cierto que en otros tipos de aplicaciones, es un disparate plantear que el desarrollo vaya guiado por pruebas sobre las especificaciones.
¿Un ejemplo? Intente escribir un ray tracer o un compilador con esta metodología. No avanzaría, se lo aseguro. ¿Por qué? Porque en el fondo, el método test-driven exige pequeños cambios incrementales en la funcionalidad y estructura del código. Sin embargo, los dos modelos de aplicaciones que he mencionado exigen el correcto funcionamiento de subsistemas realmente grandes antes de que usted pueda conectar algo y que se puedan hacer pruebas. Incluso después de ese momento, hay ciertos cambios que exigen que el programador tenga la mayor parte del modelo teórico en su cabeza para que la cosa funcione. ¡Esto es trivial, por Júpiter! Pero quien te cuenta las virtudes del test driving nunca te lo cuenta.

... y, sin embargo, de las cosas que realmente tiene que conocer el programador, pocas veces se habla. ¿Sabía usted que es más difícil comprender qué hace una aplicación orientada a objetos a partir de su código fuente, que comprender el funcionamiento de una aplicación basada en la vieja programación estructurada? ¿No me cree? Mírelo de este modo: la metodología
object oriented consiste en realizar la división modular utilizando la clasificación de entidades como principal criterio, mientras que antes se primaban los criterios funcionales. Cuando usted abre el código de XSight RT, por ejemplo, se encuentra con una clase
Sphere que "ofrece" los métodos y propiedades tales y cuales. Vale, ¿y quién usa estos métodos y propiedades? ¿Cómo empieza a rodar la bola que debe luego provocar la avalancha? ¡Ah, amigo mío, para conectar los puntos estará obligado a comprobar detenidamente el funcionamiento de la jerarquía de clases basada en
BaseSampler, y seguir las vías secundarias que conectan los
samplers con el código asociado a escenas y cámaras. Por el contrario, si XSight RT fuese una aplicación con descomposición modular funcional, habría un método
Main muy claro y visible, y usted podría entender
qué hace la aplicación en un plis plas. Es un trozo de conocimiento clásico: mientras que la programación estructura se centraba en el
cómo, la POO enfoca el
quién. Y no se puede estar en misa y repicando a la vez. ¿Se lo ha escuchado decir a alguien? Sin embargo, es de sentido común...
Sé que éste es un tema polémico. Llevo quince minutos tecleado como un poseso, y todavía me quedan explicaciones y ejemplos. Es interesante analizar por qué existe un mercado para este tipo de cosas: para las "metodologías de salvación del alma del programador" y para los remedios homeopáticos (buena comparación, por cierto). Voy a dejarlo aquí por hoy. Creo que es un debate interesante, y os animo a que os suméis y deis vuestra opinión.
 Como existe el riesgo de aburrir con este tema, voy a ser lo más breve posible. He vuelto a probar una traducción del código de XSight RT a Delphi 7 (nativo, por supuesto). Resultado: tiempos de ejecución casi idénticos, para la versión nativa y para .NET. Sorprendente, ¿verdad?
Como existe el riesgo de aburrir con este tema, voy a ser lo más breve posible. He vuelto a probar una traducción del código de XSight RT a Delphi 7 (nativo, por supuesto). Resultado: tiempos de ejecución casi idénticos, para la versión nativa y para .NET. Sorprendente, ¿verdad?

 Pero no cante aún victoria, amigo. He hecho un ensayo, para comprobar que la solución realmente funcionaba y... ¡fiasco!: el entorno de ejecución no parece efectuar la optimización necesaria. He mirado el código IL, el código nativo generado por el compilador just in time, y para estar completamente seguro, he medido los tiempos de ejecución.
Pero no cante aún victoria, amigo. He hecho un ensayo, para comprobar que la solución realmente funcionaba y... ¡fiasco!: el entorno de ejecución no parece efectuar la optimización necesaria. He mirado el código IL, el código nativo generado por el compilador just in time, y para estar completamente seguro, he medido los tiempos de ejecución. ¿Y si le cuento que, después de cerrar la versión de XSight RT incluida con los cursos para C#, he logrado reducir el tiempo de generación de imágenes a menos de la mitad, en la mayoría de las escenas?
¿Y si le cuento que, después de cerrar la versión de XSight RT incluida con los cursos para C#, he logrado reducir el tiempo de generación de imágenes a menos de la mitad, en la mayoría de las escenas?

